-
320x100

프롤로그
저는... 처음으로 HTML 파일을 봤을 때...
'이게 뭐지?' 싶어서 더블 클릭했더니 브라우저가 열려서 놀랐던 기억이 있습니다ㅋㅋㅋㅋ
사실 지금도 신기해요. 진짜 멋지죠. 그런고로 오늘은 이걸 공부해봅니다!
그래서 말입니다. 브라우저는 어떻게 동작하는 걸까요? (feat. 그알)
*이 글은 구글링을 바탕으로 작성했습니다. 추가/수정/삭제가 필요한 부분을 말씀해 주시면 감사하겠습니다 :)
브라우저
브라우저란
브라우저는 서버에 자원을 요청(reqest)하고 그걸 응답(response)해 윈도우에 표시하는 역할을 합니다.
HTML 파일이나 CSS 파일, 이미지 등이 서버에서 넘어오면 파싱(Parsing)이란 작업을 거쳐 화면에 그려냅니다.
이 과정에서 '어떻게 해석할까?'의 방식은 브라우저마다 조금씩 다릅니다. 과거에는 다들 개성이 폭발했지만, 지금은 '그래도 표준 명세가 있어야지'라는 공감 아래 웹 표준을 바탕으로 브라우저가 동작합니다.
참고로 앞으로의 HTML5 & DOM 표준은 WHATWG가 담당한다고 합니다. (출처 기사: "둘로 나뉜 웹 표준, 하나로 합쳐진다")
브라우저의 구조
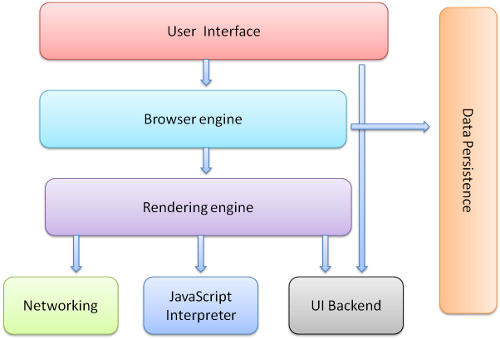
사용자 인터페이스
웹 URL을 보여주는 주소 표시 줄, 앞/뒤로 가기, 새로고침, 북마크 표시 줄 등을 뜻합니다.
브라우저 엔진
사용자 인터페이스와 렌더링 엔진 사이의 동작을 제어합니다. 주어진 URL을 읽어들이며, 앞/뒤 페이지로 가거나 새로 고침을 하는 등의 기초적인 액션을 담당합니다.
렌더링 엔진
HTML, CSS 등을 해석해주는 (아마 제가 제일 잘 친하게 지내야 할) 엔진입니다. 네트워크 계층의 데이터를 처리하고 웹 컨텐츠를 화면에 표시해 줍니다. Gecko, Trident, WebKit 등 다양한 렌더링 엔진이 존재합니다.
네트워킹
HTTP 리퀘스트와 같은 네트워크 통신을 담당합니다.
자바스크립트 해석기
자바스크립트 코드를 해석하고 실행시켜줍니다.
UI 백엔드
콤보박스, 윈도우 등 의 기본적인 위젯을 그려줍니다. OS에서 제공하는 UI 메서드를 사용합니다.
자료 저장소(Data Persistence)
로컬/세션 스토리지, 쿠키, WebSQL 등의 다양한 브라우저 API로 이루어져 있습니다.
렌더링 엔진
친해져야 할 상대를 알았으니(?) 렌더링 엔진이 어떻게 제 마크업과 스타일링을 이해하는지 살펴봅니다.
(아래 용어는 WebKit 기준입니다)
1. HTML을 파싱해 DOM 트리를 구성합니다.
2. CSS를 파싱해 CSSOM 트리를 구성합니다.
3. 두 트리를 합쳐서 렌더 트리를 만듭니다.
4. 렌더 트리에서 레이아웃을 실행해 각 노드의 형태를 계산합니다.
5. 렌더 트리의 각 노드를 화면에 페인팅합니다.
이 과정이 빠르면 빠를수록 당연히 좋겠죠?
문서가 클수록 브라우저가 수행해야 하는 작업도 더 많아지며, 스타일이 복잡할수록 페인팅에 걸리는 시간도 늘어납니다.
HTML 파싱
파싱은 제가 준 HTML을 보고 브라우저가 DOM 트리를 만드는 과정입니다.
즉, HTML과 DOM은 다릅니다. HTML은 '여기다가 헤더 만들거고, 그 아래에 타이틀 넣을 거야'라는 요구서같은 거고, DOM은 그걸 보고 브라우저가 실제로 뚝딱뚝딱 만들어 낸 결과물입니다.
HTML의 파싱 과정은 꽤나 '너그럽다'고 합니다. (가끔 닫는 태그 빼먹어도 잘 나올 때 있었던 것 같기도...)
이렇게 너그럽게 실수를 봐주었기에 HTML이 인기가 있었던 건지도 모른다고 하네요.
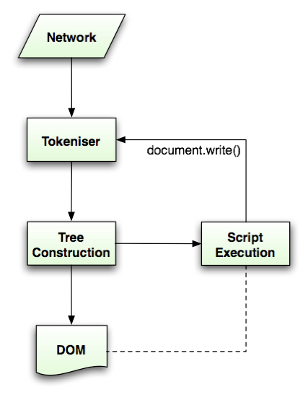
HTML 파싱 과정 토큰
HTML 내용은 '토큰화'라는 과정을 거칩니다.
토큰화는 대부분의 프로그래밍 언어에서 일반적인 파싱 프로세스로, 이해하기 쉽도록 코드를 여러 토큰으로 분할하는 것을 말합니다.

브라우저는 태그를 만나면 토큰을 만들어냅니다(emits a token).
<html><head><meta charset="utf-8"/></head><body>Hello</body></html>예를 들어,
<html>를 보면 "시작 태그가 있구나"하고 html 시작 토큰을 만듭니다.이후
<head>를 보면 "얘도 시작 태그야."라며 head 시작 토큰을 만듭니다. 이런 식으로 mata 토큰, head 종료 토큰을 만들어가다가Hello를 보면 문자 토큰을 만듭니다.
이렇게 토큰 작업이 이루어지는 동안 이 토큰들을 '노드'로 바꾸는 작업도 진행됩니다.
위의 html 토큰은 html 노드가 되고, head 토큰은 head 노드가 되는 거죠.
이 과정에서 노드간의 관계성이 생깁니다.
head 시작 토큰은 html 종료 토큰 전에 오기 때문에 head는 html의 자식이 되는 셈이죠. 트리 형태의 구조가 생긴다고 보면 됩니다.

이런 식으로 토큰을 다 소모하면 마침내 DOM이 만들어지게 됩니다.
노드
트리 구조에서 트리를 구성하는 객체를 노드(node)라고 부릅니다. 영어사전에 검색하면 node는 '나무줄기의 마디'를 뜻한다고 하네요.
HTML의 모든 것은 다 노드입니다. 심지어 독타입 선언도요! 텍스트, 주석도 물론 노드예요.
그중에 document node는 root node, 말그대로 뿌리인 노드입니다. 이를 시작점으로 노드들은 가지처럼 뻗어난 형태를 가집니다.
이렇게 아래로 뻗어나가면서 위에 있는 노드는 부모가 되고, 아래 있는 노드는 자식이 됩니다.
자식이 없는 노드는 leaf node라고도 합니다. (이름 참 잘 지었네요)
이처럼 DOM은 노드라는 가지와 잎이 난 하나의 나무라고 볼 수 있겠습니다.
DOM
DOM(Document Object Model)이란 HTML 및 XML 문서를 위한 API입니다.
DOM은 document(웹페이지)의 문서의 논리적 구조를 노드의 계층 구조 트리로 나타냅니다.
개발자는 자바스크립트를 통해 DOM에 접근하고 조작할 수 있습니다.
HTML과 마찬가지로 DOM도 W3C에서 정한 명세가 있습니다.
참고 글
How Browser Works (*위 글의 원문) - html5rocks
How Do Web Browsers Work? - Hackernoon
Converting HTML to DOM - Udacity
Web Render-Tree Construction, Layout, and Paint - Google Developers
시리즈의 다음 글: 브라우저의 동작 (2) - CSS : 내 말대로 꾸며줘!
728x90'Blog > etc.' 카테고리의 다른 글
브라우저의 동작 (3) - 웹 페이지 최적화 (3) 2020.06.12 브라우저의 동작 (2) - CSS : 내 말대로 꾸며줘! (0) 2020.06.09 [되짚기] 초보를 위한 Git 다루기 / 풀리퀘하기 (2) 2020.04.16 웹 퍼블리셔를 위한 VS CODE 확장 프로그램 (2) 2020.04.05 [DP] Web Publishing Copy - Studio JT (1) 2019.10.31 댓글
nana_log
좋아하는 걸 좋아하는 나나 🤟
